Web 01
개요
굉장히 많은 것들을 배웠다. 근데 명확하게 정리되지 않는 것 같아서 한 번 정리하고 넘어가려고 한다.
웹
웹은 인터넷 상에서 어떻게 정보를 공유할 건지에 대한 해답이다. 정보들의 형식으로 HTML, 방대한 인터넷 망에서 특정 자원을 식별하기 위한 수단으로 URI(Uniform Resource Identifier)라는 개념이 사용되기 시작했다. 그리고 전송 규약으로 HTTP를 사용한다.
우선 HTML은 Hyper Text Markup Language의 약자로 여기서 하이퍼 텍스트란 우리가 흔히 접하는 링크라고 보면 된다.
처음엔 단지 링크를 이용해 다른 사이트를 연결하고 정보를 정적으로 제공하는데 그쳤지만 현대의 웹은 단순한 정보제공 뿐만 아니라 여러 동적인 작업도 수행한다. 디자인도 입히고 자바스크립트로 동적인 액션도 취할 수 있는 웹까지 진화했다.
여기서 특정 정보는 그냥 인터넷 상에 언제든지 위치하고 있는 것이 아니라 서버에 요청을 보내서 응답을 받아야한다.(HTTP 프로토콜) 이때 응답을 해주는 컴퓨터가 바로 웹 서버이다.
웹의 두가지 카테고리
웹은 프론트엔드(FE)와 백엔드(BE)로 나뉜다.
우리가 인터넷을 하기위해서 브라우저에서 웹을 탐색하곤하는데 이 때 브라우저를 프론트엔드 또는 클라이언트라고 한다.
여기서 주의해야할 것은 웹에서 클라이언트는 클라이언트의 원래 쓰임과는 조금 다르다. 실생활에선 사람이나 어떤 단체를 말하지만 웹에서 클라이언트는 요청을 보내고 받는 브라우저를 말한다.
클라이언트가 요청을 보내고 받는 대상이 바로 백엔드이다.
직관적으로 보면 프론트엔드는 앞에있어 프론트, 백엔드는 뒤에있어 백엔드인 것이다.
웹 프론트엔드
웹은 사용자에게 웹을 통해 다양한 콘텐츠를 제공한다.
프론트엔드의 역할은 다음과 같다.
- 웹 콘텐츠를 잘 보여주기 위해 구조를 만들어야한다.
- 적절한 배치와 일관된 디자인을 제공해야한다.
- 사용자의 요청을 잘 반영해야한다. 프론트엔드의 구성
웹 백엔드
백엔드는 정보를 처리하고 저장하며 요청에 따른 정보를 반환해주는 역할을 한다.
브라우저
웹을 통해서 전달되는 데이터는 어디선가 해석되어야한다. 서버에서 전송한 데이터가 도착하는 곳이 바로 브라우저다.
브라우저는 월드와이드웹(WWW)에서 정보를 검색, 표현하고 탐색하기 위한 소프트웨어이다.
브라우저는 서버가 보내준 데이터를 해석해주는 엔진이 포함되어있는데 이를 렌더링 엔진이라 부른다.
브라우저를 살펴보면 어느 브라우저나 공통적으로 존재하는 요소들이 있다.
브라우저에는 특정 정보로 이동할 수 있는 주소창이 있고 서버와 정보를 주고받기 위한 네트워크 모듈이 있다.
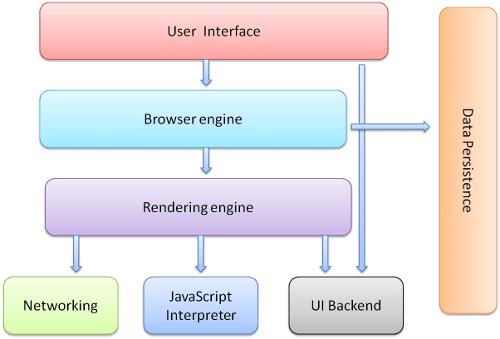
쉽게 요약하자면 브라우저는 HTML을 해석해서 DOM Tree를 그리고 HTML의 문서구조를 파악한다.
그리고 css를 해석해서 CSS Tree를 그린다. 그리고 이 두개는 연관되어있으므로 Render Tree로 다시 조합된다.
이렇게 조합된 결과는 요소들을 화면의 어떤 위치에 어떻게 배치할 것인지에 대한 정보를 담고있다.
(이 부분에 대해 좀 더 공부해본다면 리액트의 등장 배경을 알 수 있다.)
고전적인 웹
스프링이 등장하기 이전의 웹은 JAVA EE 라는 기술스펙을 이용했다.
웹을 구현하기 위한 고민들을 하나로 묶어 방대한 기술스펙으로 제공한 것이 JAVA EE이다.
JAVA EE의 주요 기술 스펙은 서블릿과 JSP로 서버측에서 데이터를 처리할 수 있도록 하는 서버사이드 프로그래밍 방식의 접근이다.
서블릿
서블릿은 서버에서 동적으로 요청과 응답을 처리할 수 있는 API들을 정의한 것이다.
서블릿을 지원하는 환경에서 개발자들은 서블릿에서 제공하는 API을 이용해서 코드를 작성하는 방식으로 프로그램을 작성하게 된다.
서블릿은 주로 HttpServlet클래스를 상속받아 사용하는데 메소드로는 대표적으로 doGet, doPost등이 있다.GET요청을 받을 때 사용하고 doPOST메소드는 POST요청을 받을 때 사용한다.
인자로는 HttpServletRequest 와 HttpServletResponse가 있는데 리퀘스트는 사용자의 요청에 대한 정보를 담고있고 리스폰스는 사용자에게 응답을 할 수 있는 메소드를 포함하고 있다.
서블릿은 다음과 같이 사용할 수 있다.
@WebServlet("/example")
public class ExamController extends HttpServlet {
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
resp.setContentType("text/html;charset=utf-8");
PrintWriter out = resp.getWriter();
out.println("<h1>Test</h1>");
out.close();
}
}
@WebServlet은 어떤 경로로 오는 요청을 받을 것인지 나타낸다.
서블릿 버전 3.0 이전에는 web.xml에 정의해두는 방식이였지만 서블렛 3.0이후부턴 간단하게 어노테이션만 붙이면 사용할 수 있다.
구조를 보면 HttpServlet을 상속받고 있고 doGet이라는 메소드를 오버라이딩해서 사용하고 있는 것을 알 수 있다.
위와 같은 방법으로 브라우저에 간단한 문구를 화면에 출력할 수 있는데 resp.setContentType("text/html;charset=utf-8");로 PrintWriter의 출력 인코딩 형식을 정할 수 있다.
고전적인 웹의 경우 위와같이 리스폰스 객체에서 PrintWriter객체를 얻어와 출력문 안에 한 줄 한 줄 HTML코드를 넣었다고 한다.
JSP
마이크로소프트의 ASP(Active Server Pages)와 같은 스크립트 형태의 개발 방법이 인기를 얻게 되면서, 자바 진영에서도 대항하기 위해서 JSP를 발표하게 된다.
JSP는 근본적으로 서블릿과 같은 원리이지만(실제로 jsp가 컴파일된 class파일을 살펴보면 서블릿코드로 변환된 것을 볼 수 있다) 자바 코드 기반에 HTML코드를 넣는 서블릿과 달리 HTML코드 기반에 자바 코드를 넣을 수 있다는 장점이 있다.
이 때 이들이 동작하는 환경은 서블릿 컨테이너라고 하는데 현재 톰캣이 서블릿 컨테이너의 역할을 하고 있다.
서블릿 코드를 실행하는 주체는 톰캣과 같은 서블릿 컨테이너이므로 객체를 생성하거나 호출하는 등의 작업을 서블릿 컨테이너가 수행하게 된다.
서블릿과 JSP는 상호보완적인데 서블릿은 자바 로직을 구현하는데 특화되어있고 JSP는 화면을 출력하는데 특화되어있다.
그래서 서블릿을 이용한 웹 개발을 한다면 각각을 제한된 용도로 사용하게 된다.
브라우저의 요청은 해당 주소를 처리하는 서블릿에 전달되고 서블릿 내부에서는 응답에 필요한 재료데이터들을 준비한다. 그리고 서블릿은 이 데이터들을 JSP로 전달하고 JSP에서는 EL을 이용해서 최종적인 결과를 만들어낸다.
이런 구조를 MVC라고 하는데 MVC는 Model-View-Controller의 약자이다. 컨트롤러는 사용자의 요청을 받고 처리하고 뷰는 처리된 결과를 보여준다.
모델은 이 컨트롤러와 뷰 이외의 자바 클래스들을 말한다.
여기선 서블릿이 컨트롤러의 역할을 하고 JSP가 뷰의 역할을 한다.
서블릿은 싱글톤이라는 디자인 패턴을 사용하는데 객체를 한 번만 생성하고 이걸 재사용하는 방식이다.
실제로 서블릿의 init,service,destroy메소드를 오버라이드해서 테스트해보면 init과 destroy는 프로그램의 실행과 종료시점에 한 번씩만 실행되고 다시 요청을 보내도 service메소드만 실행되는 것을 확인할 수 있다.
서블릿 객체에서 요청을 처리하는 doGet,doPostsms HttpServletRequest와 HttpServletResponse를 파라미터로 전달받는다. req객체는 HTTP메시지 형태로 들어오는 요청에 대한 정보를 파악하기 위한 객체인데 주요 메소드는 다음과 같다
- HTTP 헤더 관련 - HTTP 해더 내용들을 찾아내는 기능
- getHeaderNames()
- getHeader()
- 사용자 관련 - 접속한 사용자의 IP주소
- getRemoteAddress()
- 요청 관련 - GET/POST 정보, 사용자가 호출에 사용한 URL정보
- getMethod()
- getRequestURL()
- getRequestURI()
- getServletPath()
- 쿼리스트링 관련 - 쿼리 스트링 등으로 전달되는 데이터를 추출하는 용도
- getParameter()
- getParameterValues()
- getParameterNames()
- 쿠키 관련 - 브라우저가 전송한 쿠키 정보
- getCookies()
- 전달 관련
- getRequestDispatcher()
- 데이터 저장 - 전달하기 전에 필요한 데이터를 저장하는 용도
- setAttribute()
여기서 주로 사용하는 것은 getParameter()메소드로 인터넷 주소창을 보면 주소의 끝 부분에 ?name=Jun&age=20과 같은 문자열을 볼 수 있는데 이런 방식을 쿼리스트링이라고 부른다.
등호를 기준으로 왼쪽은 키, 오른쪽은 값이다. 여러개의 키와 값이 존재할 경우 & 를 통해서 연결시킨다.
https://www.boostcourse.org/web316/lecture/16702?isDesc=false와 같이 주변에서 흔하게 찾아볼 수 있다.
getParameterValues는 동일한 이름의 파라미터가 여러개 존재하는 경우에 사용한다.
setAttribute는 JSP로 전달할 데이터를 추가할 때 사용한다.
형식은 키와 값의 형태이고 키는 문자열, 값은 모든 객체타입을 사용할 수 있다.
RequestDispatcher는 컨트롤러인 서블릿이 데이터 처리를 마치고 JSP에 전달해주는 용도로 사용한다.
여기는 두가지 메소드가 존재하는데 forward(), include()이다. 주로 forward를 많이 사용한다.
HttpServletResponse의 주요 기능
- setContentType()
- setHeader()
- setStatus()
- getWriter()
- addCookie()
- sendRedirect()
주로 sendRedirect가 많이 사용된다.
sendRedirect는 다른곳으로 가라는 응답 메시지를 전달한다.
HTTP에서 Location이라는 이름의 HTTP헤더로 전달되는데 브라우저는 Location이 있는 응답을 받으면 주소창에 지정된 주소로 이동하고 다시 호출하게 된다.
이를 사용하면 브라우저의 주소가 아예 변경되기 때문에 사용자의 새로고침과 같은 요청을 미리 방지할 수 있다.
이는 요청을 두 특정한 작업이 끝나고 완전히 새로 시작하는 흐름을 만들 수 있다. 이러한 패턴을 PRG(Post Redirection Get)패턴이라고 부른다. 우리가 웹사이트에서 회원가입을 하거나 게시글을 등록하는 등의 작업을 했을 때 흔히 볼 수 있는 패턴이다.