Web 02
개요
자바 프로그램에서 데이터베이스를 사용하는 방법에 대해 알아보자.
JDBC
Java Database Connectivity는 자바 프로그램에서 데이터베이스를 사용하기 위해 자바에서 제공하는 데이터베이스 API이다. 인터페이스란 말은 구현체가 필요하다는 말인데 구현체는 각 데이터베이스 벤더사가 제공해주고 있다. JDBC는 데이터베이스와 자바프로그램 사이에서 네트워크 데이터를 처리하는 코드가 필요한데 JDBC드라이버가 이러한 역할을 수행한다.
JDBC를 이용한 프로그래밍 시나리오는 다음과 같다.
- 드라이버를 로드한다.
Connection객체를 생성해 데이터베이스와 네트워크 연결을 맺는다.Statemet객체를 생성 및 질의 수행- 결과물이 있는 질의라면
ResultSet객체를 이용해 데이터를 받는다. - 모든 객체를 닫는다.
여기서 사용한 객체를 닫아주는 이유는 데이터베이스는 굉장히 많은 연결을 처리해야 하는데 각 작업이 종료되지 않으면 새로운 연결을 받을 수 없는 상황이 발생한다. close()메소드는 데이터베이스쪽에 연결을 끊어도 좋다는 신호를 주고 네트워크 연결을 종료한다.(데이터베이스 연결은 실제 TCP/IP 연결로 말그대로 연결되어있다.)
public int addTodo(TodoDto dto) {
String sql = "insert into todo(title, name, sequence) values(?, ?, ?);";
int addCount = 0;
try (Connection conn = DriverManager.getConnection(dburl, dbuser, dbpw);
PreparedStatement ps = conn.prepareStatement(sql)){
ps.setString(1, dto.getTitle());
ps.setString(2, dto.getName());
ps.setInt(3, dto.getSequence());
try {
addCount = ps.executeUpdate();
} catch(Exception e) {
e.printStackTrace();
}
} catch(Exception e) {
e.printStackTrace();
}
return addCount;
}
반드시 종료되어야한다라는 키워드를 들었을 때 자바에 익숙하다면 try catch finally구문을 떠올릴 것이다.
이를 사용해도 좋고 try with resources라는 구문이 있는데 객체를 자동으로닫아주어 객체의 close가 보장된다.
Lombok에서는 @Cleanup이라는 애노테이션만 붙임으로써 객체의 close()를 보장할 수 있다.
커넥션을 맺은 다음에 가장 중요한 객체는 Statement 혹은 PreparedStatement이다.
이 객체들은 sql을 실행할 수 있는 객체를 생성하는 기능인데 Connection객체로부터 얻어올 수 있다.
두 객체는 쿼리문을 전달한다는 점에선 같지만 쿼리문 내무의 모든 데이터를 같이 전송하는 방식과(Statement) 쿼리문을 미리 전달하고 나중에 데이터를 보내는 방식(PreparedStatement)이라는 점에서 다르다.
실제 개발에서는 PreparedStatement만을 사용하는 것이 관례라고 한다. 이는 SQL내부에서 고의적으로 다른 처리가 가능한 SQL injection을 막기 위함이다.
Connection conn = DriverManager.getConnection(url, user, password);
PreparedStatment ps = conn.prepareStatement("쿼리문");
주요 메소드는 setXXX()로 다양한 데이터 타입에 맞게 데이터를 세팅할 수 있다.
executeUpdate() 쿼리문을 수행하고 결과를 int타입으로 반환한다.
메소드의 이름에서 알 수 있듯이 insert,update,delete등 테이블에 영향을 미치는 쿼리문에 테이블의 몇 개의 행이 영향을 받았는지 알 수 있다.
executeQuery() select문을 실행할 때 사용한다.
executeQuery는 ResultSet을 리턴 타입으로 갖는다.
커넥션과 마찬가지로 닫아줘야 데이터 베이스 내부에서 메모리와 같이 사용했던 자원들이 정리된다.
ResultSet이라는 인터페이스를 통해 자바 코드에서 데이터를 읽어들인다. 그래서 getXXX()와 같이 필요한 타입으로 데이터를 받는다. 여기서 next()라는 메소드가 중요한데 데이터를 순차적으로 읽는 방식으로 작동하기 때문에 여려 row의 데이터가 있을 때 다음 행으로 이동하는 작업이 필요하다. 역시 네트워크를 통해서 데이터를 읽어들이기 때문에 작업이 끝난 후에는 반드시 close()를 사용해주어야 데이터베이스에서도 즉각적으로 정리할 수 있다.
Connection Pool과 DataSource
JDBC 프로그래밍은 필요한 순간에 잠깐 데이터베이스와 네트워크로 연결하고 데이터를 주고 받는 방식으로 구성되는데 이 과정에서 데이터베이스와 연결을 맺는 작업은 많은 시간과 자원을 쓰기 때문에 SQL문을 여러번 수행할수록 성능저하를 피할 수 없게 된다. 이를 위한 솔루션이 바로 ConnectionPool이다.
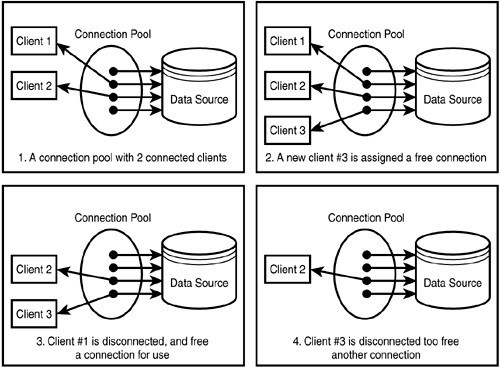
커넥션 풀은 미리 커넥션을 여러개 맺어두고 커넥션이 플요하면 커넥션 풀에게 빌려서 사용한 후 반납한다.
데이터 소스는 커넥션풀을 관리하는 목적으로 사용된다. 커넥션을 얻고 반납하는 등의 작업을 수행한다. 위에서 살펴본 클로즈 메소드는 커넥션을 반납하도록 구현이 되어있다.
인터페이스로 커넥션 풀을 이용하는 라이브러리들은 모두 데이터소스 인터페이스를 구현하고 있다. 커넥션 풀은 DBCP나 C3PO, HikariCP등이 있다.
여기서 잠깐 생각을 해보자면 JDBC를 고전적으로 사용할 때 커넥션 생성할 때 데이터 베이스에 접속하기 위한 정보들을 넣어줬다. 그럼 커넥션풀과 데이터소스를 사용한다면 어디에 이런 정보를 넣어줘야할까? 커넥션 플을 관리하고 커넥션을 얻어오는 데이터 소스 객체에 넣어주는게 맞겠다.
Spring JDBC
JDBC를 이용해서 프로그래밍을 하게 되면 반복적인 코드가 많이 발생한다.
네트워크 자원을 얻어오고 반환하고 반복되는 쿼리를 작성하고
이러한 반복적인 코드는 개발자의 생산성을 떨어트리는 주된 원인이 된다.
이러한 문제를 해결하기 위해 등장한 것이 Spring JDBC다. Spring JDBC는 모든 저수준 세부사항을 스프링 프레임워크가 처리해준다.
-
Spring JDBC 패키지
- org.springframework.jdbc.core
JdbcTemplate 및 관련 Helper 객체 제공 - org.springframework.jdbc.datasource
DataSource를 쉽게 접근하기 위한 유틸 클래스, 트랜젝션매니져 및 다양한 DataSource 구현을 제공 - org.springframework.jdbc.object
RDBMS 조회, 갱신, 저장등을 안전하고 재사용 가능한 객제 제공 - org.springframework.jdbc.support
jdbc.core 및 jdbc.object를 사용하는 JDBC 프레임워크를 지원
- org.springframework.jdbc.core
-
JDBC Template
org.springframework.jdbc.core에서 가장 중요한 클래스다.
리소스 생성, 해지를 처리해서 연결을 닫는 것을 잊어 발생하는 문제 등을 피할 수 있도록 한다.
스테이먼트(Statement)의 생성과 실행을 처리한다.
SQL 조회, 업데이트, 저장 프로시저 호출, ResultSet 반복호출 등을 실행한다.
JDBC 예외가 발생할 경우 org.springframework.dao패키지에 정의되어 있는 일반적인 예외로 변환시킨다.
주요 클래스 및 인터페이스
- NamedParameterJdbcTemplate
기존 JDBC에서 sql쿼리 안에 ?로 표현되던 파라미터를 자바 네이밍 컨벤션으로 이름을 붙여서 지정할 수 있다. 좀 더 명확하며 물음표의 순서에 구애받지 않는다. 이 클래스는 DataSource 객체를 필요로 하는데 다음과 같이 생성자에서 주입받으면 된다.
private NamedParameterJdbcTemplate jdbc; private SimpleJdbcInsert insertAction; private RowMapper<Role> rowMapper = BeanPropertyRowMapper.newInstance(Role.class); public RoleDao(DataSource dataSource) { this.jdbc = new NamedParameterJdbcTemplate(dataSource); this.insertAction = new SimpleJdbcInsert(dataSource) .withTableName("role"); } public List<Role> selectAll(){ return jdbc.query(SELECT_ALL, Collections.emptyMap(), rowMapper); } - RowMapper
ResultSet에서 원하는 객체로 타입을 변환하는 역할을 한다. - BeanPropertyRowMapper
기존의 JDBC에서ResultSet를 사용해 원하는 자료형으로 데이터를 받고 DTO의 setter를 이용해 정보를 넣어줬다.RowMapper를 사용하면 자바의 클래스로 바로 받을 수 있다. SQL과 자바는 네이밍 컨벤션이 다르다. SQL은 단어와 단어 사이를_로 연결하는 반면 자바의 클래스는 단어와 단어를 시작하는 단어의 첫 알파벳을 대문자로 설정하는데RowMapper는 이런 부분을 자동으로 변환해준다. - SqlParameterSource
직접 플레이스 홀더와 값을 입력해주지 않더라도 쿼리의 파라미터를 지정해줄 수 있다.
자바 객체의 필드명과 값을 읽어와서 파라미터 맵을 생성한다. - SimpleJdbcInsert
INSERT INTO 테이블명(속성명) VALUES(값)
굉장히 간단한 문법이다. 속성명과 값만 알면 데이터를 삽입할 수 있다.
public int insert(Role role) {
SqlParameterSource params = new BeanPropertySqlParameterSource(role);
return insertAction.execute(params);
}
SimpleJdbcInsert를 활용하면 직접 INSERT 쿼리를 작성하지 않고도 DB에 데이터를 저장할 수 있다. DB 컬럼명과 객체의 속성명이 일치한다면 아래와 같은 단순한 코드로 DB에 데이터 1건을 입력할 수 있다.
때론 데이터베이스에 입력이 완료된 후 그 PK값을 받아서 사용해야하는 경우가 있을 수 있다. 그럴 때엔 insertAction.executeAndReturnKey(param)메소드를 사용하면 PK값을 받아올 수 있다.
만약 직접 쿼리를 작성해서 insert하고싶은 경우가 있을 수 있다.
자바의 객체에 createdAt필드가 있어서 LocalDateTime.now()와 같이 현재 시각을 구한 뒤 이를 넣어주면 SimpleJdbcInsert로도 충분하다. 그러나 요청이 처리되었다는 것은 DB에 기록이 되었다는 의미이므로 애플리케이션 서버에서 이를 정해주는 것 보다는 DB에 입력된 시각을 createdAt으로 보는 것이 좀 더 리즈너블하다.
따라서 이런 경우 DB의 NOW()함수를 사용하여 기록할 수 있다.
이렇게 되면 직접 쿼리를 작성해주어야하는데 executeAndReturnKey와 같이 테이블에 입력하고 키를 리턴받는 방법은 KeyHolder keyHolder = new GeneratedKeyHolder();를 사용하는 것이다.
jdbc.update(쿼리, params, keyHolder);
return keyHolder.getKey().intValue();
이렇게 하면 DB에 저장된 키 값을 사용할 수 있다.